Modelos de atribución: corrige el sesgo que distorsiona tus resultados
Los modelos de atribución son la brújula que muchos equipos de marketing usan para decidir dónde invertir. Si la brújula está descalibrada, las decisiones pueden llevar a perder oportunidades y malgastar presupuesto. Esta realidad no es una teoría elegante: es un problema cotidiano en departamentos de marketing, agencias y equipos de analítica.
En este texto vamos a analizar por qué los modelos de atribución fallan con frecuencia, cuáles son los sesgos que distorsionan los resultados y qué alternativas prácticas existen para reducir ese error. No busco confundir con jerga técnica innecesaria; mi objetivo es que salgas con herramientas aplicables, tanto si diriges un equipo como si eres consultor o investigador.
La aproximación que propongo combina fundamentos conceptuales, referencias a autores relevantes y pasos operativos claros. Veremos desde los modelos tradicionales hasta soluciones basadas en teoría de juegos como el valor de Shapley y en experimentación. Cada bloque tendrá ejemplos sencillos y recomendaciones de implementación.
¿Qué es un modelo de atribución y por qué importa?
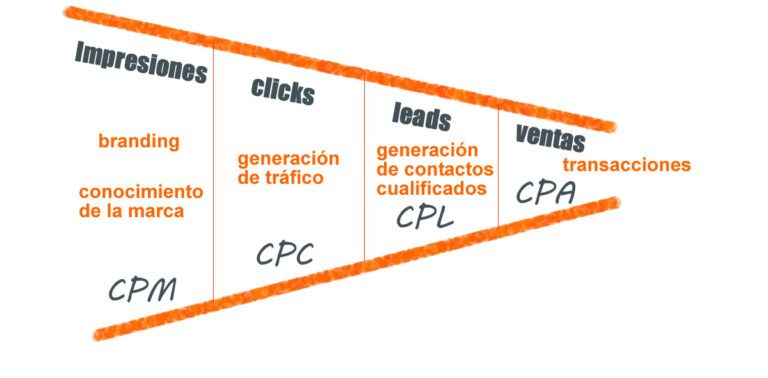
Un modelo de atribución en marketing es, en esencia, un sistema de reparto. Su función es decidir qué parte del mérito de una venta (o conversión) corresponde a cada interacción que tuvo el cliente antes de comprar.
Piensa en esto sin tecnicismos: una persona ve un anuncio en Instagram, luego busca en Google, entra en tu web, se suscribe a una newsletter y días después compra tras recibir un email.
La pregunta clave es: ¿quién “provocó” la venta?
¿Instagram? ¿Google? ¿el email?
Un modelo de atribución es la regla que se usa para responder a esa pregunta.
Si el modelo es simplista o sesgado, las acciones derivadas también lo serán. Esto provoca dos consecuencias claras: la sobrevaloración de canales que aparecen cerca del momento de compra y la infravaloración de actividades que generan valor de forma indirecta o a largo plazo. En ambos casos se afecta la estrategia y el retorno a medio y largo plazo.
Sirve para tomar decisiones de dinero. Concretamente:
- Decidir dónde invertir más presupuesto
- Saber qué canales funcionan realmente
- Optimizar campañas (quitar lo que no aporta y escalar lo que sí)
- Justificar resultados frente a dirección o clientes
Si la atribución no es correcta, no es un problema teórico: pierdes dinero.
La discusión sobre atribución es también organizativa. La elección de un modelo impacta incentivos internos, remuneraciones y la forma en que se mide el rendimiento. Por eso abordar el sesgo requiere trabajo colaborativo entre analítica, medios, producto y dirección.
Panorama de modelos tradicionales y sus sesgos
Los modelos clásicos van desde el último contacto (last touch) hasta el modelo lineal multitoque (multi-touch linear). Cada uno incorpora supuestos implícitos que introducen sesgos. El último contacto (last touch) asigna todo el crédito al último punto de contacto, mientras que el primer contacto (first touch) lo hace con el primero. El modelo lineal (linear model) reparte el valor de forma equitativa y el decaimiento temporal (time decay) prioriza las interacciones más recientes.
 Estos modelos son útiles por su simplicidad. Sin embargo, esa simplicidad implica que no capturan la complejidad real del recorrido del cliente. El sesgo más común es la sobrevaloración de tácticas tácticas y de performance inmediatas, a menudo representadas por publicidad buscada o retargeting, frente a esfuerzos de branding o contenido educativo que actúan en etapas tempranas.
Estos modelos son útiles por su simplicidad. Sin embargo, esa simplicidad implica que no capturan la complejidad real del recorrido del cliente. El sesgo más común es la sobrevaloración de tácticas tácticas y de performance inmediatas, a menudo representadas por publicidad buscada o retargeting, frente a esfuerzos de branding o contenido educativo que actúan en etapas tempranas.
Otro sesgo relevante es el de posición. Los modelos que asignan peso fijo a la primera y última interacción dan por hecho que esos puntos son los más importantes, pero no siempre es así. Dependiendo del ciclo de decisión, la investigación previa o la venta consultiva, los puntos intermedios pueden ser decisivos y quedan invisibilizados.
Sesgos de medición y datos
Más allá del modelo, los datos que alimentan la atribución suelen tener problemas: fragmentación cross-device, borrado de cookies, pérdida de datos por bloqueadores, atribuciones offline mal registradas y discrepancias entre plataformas. Estos fallos generan sesgos adicionales que distorsionan la asignación de valor.
Un ejemplo habitual es medir conversiones sin conectar con CRM. Las conversiones digitales se asignan a canales online mientras las ventas reales pasan por vendedores que usan leads generados por múltiples fuentes. Sin integración, el valor real de canales como contenidos o eventos se pierde.
Otro fenómeno es el sesgo de supervivencia: las interacciones que perduran en el conjunto de datos son las que sobreviven a filtros y segmentaciones. Esto puede favorecer canales con medición robusta frente a canales que aportan valor pero son más difíciles de trackear.
El sesgo maestro: lo que no ves en la atribución
Existe un sesgo transversal que voy a llamar el sesgo maestro: la tendencia a explicar la conversión con lo que el sistema puede medir. Si un canal no deja rastro cuantificable en tu stack, su contribución tiende a desaparecer del análisis. Eso no significa que no influya en la decisión del cliente; significa que tu modelo tiene un agujero.
Este sesgo alimenta decisiones equivocadas: recortar inversión en brand porque las conversiones atribuidas son bajas, reducir contenido educativo por su lenta conversión o cancelar patrocinios por la falta de un pixel que los atribuya. En términos prácticos, se confunde ausencia de evidencia con evidencia de ausencia.
Para combatir este sesgo hay que adoptar una postura crítica frente a los datos y complementar modelos con evidencia cualitativa, con experimentación y con técnicas que puedan imputar valor a interacciones incompletas. La combinación de métodos reduce la incertidumbre y ofrece una visión más robusta.
Modelos avanzados: cuándo y cómo evitarlos
Los modelos basados en datos (data-driven) intentan aprender patrones de contribución a partir de datos históricos. Son un avance respecto a las reglas fijas, pero no son mágicos. Su calidad depende de la exhaustividad y la integridad de los datos. Si la entrada (input) está sesgada, la salida (output) también lo estará.
Una alternativa teóricamente sólida es el uso del valor de Shapley (Shapley value), procedente de la teoría de juegos (game theory). Shapley asigna el crédito en función de la contribución marginal de cada “jugador” en todas las permutaciones posibles. En atribución, esto permite valorar de forma más equitativa el aporte de cada canal, considerando combinaciones y sin privilegiar la posición.
Aplicar Shapley tiene costes computacionales y requiere datos limpios. No siempre es la mejor opción desde un punto de vista de coste-beneficio (cost-benefit), pero resulta especialmente útil cuando se quiere entender el valor real de interacciones complejas y cuando se dispone de un volumen de datos suficiente.
Limitaciones y precauciones en modelos avanzados
Los modelos complejos pueden falsear la sensación de certeza. Un algoritmo que entrega números con precisión aparente no corrige problemas de integridad de datos ni evita que decisiones organizativas sesguen el uso de los resultados. La transparencia en los supuestos y en la calidad de los datos es clave.
Además, los modelos avanzados suelen requerir interpretación experta. No es suficiente implementar un modelo de Shapley o machine learning; hay que entender qué implican los outputs para la estrategia y cómo se traducen en cambios operativos en compra de medios, creatividades o producto.
Finalmente, la robustez del modelo debe contrastarse con experimentos controlados. Los modelos pueden señalar hipótesis; los experimentos las verifican. Sin validación experimental, cualquier modelo es una sugerencia, no una verdad garantizada.
Experimentación práctica: la forma más sólida de validar atribución
La experimentación es la herramienta más directa para reducir el sesgo. Tests aleatorios, pruebas A/B a nivel de canal o levantamiento y caída de inversión permiten medir impacto incremental real. A diferencia de la atribución observacional, los experimentos estiman causalidad.
Un diseño experimental puede consistir en dividir audiencias o mercados y variar la exposición a un canal. Por ejemplo, suspender una campaña de display en un territorio y comparar la evolución de ventas con territorios control. Si la infraestructura lo permite, estos ensayos ofrecen la evidencia más robusta sobre la contribución incremental.
La experimentación exige coordinación, tamaño muestral y respeto por el periodo de observación. Además, suele ser más costosa y lenta que aplicar modelos directos. No obstante, sus resultados permiten calibrar modelos y justificar decisiones de inversión con mayor convicción.
¿Cómo combinar modelos y experimentos?
Lo más efectivo es usar un enfoque híbrido. Los modelos de atribución ofrecen diagnósticos continuos y operativos. Los experimentos validan o corrigen esos diagnósticos. Si un modelo sugiere que cierto canal multiplica conversiones, diseña un experimento para medir su efecto incremental y cuantificar el retorno real.
La experimentación también ayuda a ajustar parámetros de modelos data-driven: tasas de conversión condicionales, ventanas de atribución y pesos por posición. Cuando los experimentos confirman la magnitud del efecto, los modelos ganan legitimidad para automatizar decisiones tácticas.
Finalmente, documenta siempre la metodología y comparte resultados con stakeholders. Los experimentos generan aprendizajes transversales que afectan a producto, pricing y atención al cliente, no solo a medios.
Implementación práctica paso a paso
- Diagnóstico inicial: revisa la calidad de datos. Comprueba integraciones entre web, app y CRM. Verifica tasas de deduplicación, atributos de canal y pérdidas por cross-device. Este paso revela brechas que condicionarán cualquier modelo.
- Selección de modelo base: elige un modelo simple para empezar. Puede ser un modelo lineal o un modelo posicional por defecto que sirva como referencia operativa. La clave es tener un baseline que puedas comparar con alternativas más avanzadas.
- Complementa con analítica cualitativa: recoge inputs comerciales, feedback de fuerza de ventas y estudios cualitativos. Estos datos no cuantitativos ayudan a asignar hipótesis sobre el papel de cada canal, especialmente para actividades offline o de marca.
- Diseña experimentos para canales críticos: identifica las apuestas de mayor presupuesto o incertidumbre y planifica pruebas controladas. Define métricas de éxito, periodos y tamaños de muestra. Mantén la coherencia con los objetivos de negocio, no solo con clicks o impresiones.
- Implementa modelos avanzados con cautela: cuando dispongas de datos adecuados, prueba modelos data-driven o métodos como Shapley en un entorno de análisis. No los uses automáticamente para redistribuir todo el presupuesto sin validar con experimentos.
- Itera y gobierna: crea un proceso de revisión periódica donde analítica, medios y dirección revisen resultados, supuestos y experimentos. La atribución no es una tarea puntual; es una disciplina en evolución que requiere gobierno y comunicación
Herramientas y consideraciones técnicas
En la práctica, la elección de herramientas depende del es el conjunto de herramientas, plataformas y sistemas que una empresa utiliza para operar una función concreta, en este caso marketing. y del tamaño del negocio. Plataformas de analítica con capacidades de atribución, sistemas de data warehouse y soluciones de modelado en Python o R suelen ser suficientes. Para Shapley y modelos complejos, a menudo se utilizan librerías estadisticas específicas y capacidad de cómputo para procesar permutaciones.
Un aspecto crítico es la integración con CRM y sistemas de facturación. Sin esa integración, la medición de impacto en ventas reales suele ser parcial. Prioriza crear pipelines de datos que conecten fuentes y permitan reconstruir la ruta del cliente con la mayor fidelidad posible.
Finalmente, documenta pipelines, diccionarios de datos y transformaciones. La reproducibilidad es vital para auditar sesgos y tomar decisiones basadas en evidencia replicable.
Ejemplos aplicables: B2B y B2C
En B2B, el ciclo de compra suele ser más largo y consultivo. Un webinar, una llamada comercial y contenido técnico pueden ser etapas decisivas. Un modelo last touch que privilegie el clic final de búsqueda infravalora el trabajo de generación de confianza. En este contexto, el uso de modelos que valoren la contribución de puntos intermedios y la evidencia de experimentos segmentados por cuenta es esencial.
En B2C, ciclos cortos y volumen permiten modelos basados en datos más robustos, pero también una mayor exposición al sesgo de medición. El reto en B2C suele ser la atribución cross-device y la medición del impacto de branding. Aquí las pruebas de incrementabilidad y la triangulación entre modelos observacionales y experimentales son prácticas recomendadas.
Un ejemplo práctico: una marca B2C ajustó su inversión reduciendo display por atribución last touch y vio caer la intención de compra en tests control. Al integrar experimentos y aplicar Shapley a su dataset, reconoció que display tenía un efecto significativo en la recuperación de carritos y en la visibilidad de promociones, lo que justificó mantener parte de la inversión.
Decisiones organizativas que afectan la atribución
La forma en que un equipo organiza sus incentivos altera la interpretación de la atribución. Si los objetivos se centran en CPA corto plazo, los modelos tenderán a optimizar tácticas de conversión inmediata. Esto puede ser racional desde un punto de vista económico, pero estratégico desde la perspectiva de la marca resulta miope.
La solución pasa por equilibrar objetivos y métricas. Integrar KPIs de marca, métricas de retención y valor de vida del cliente en la evaluación reduce la tentación de optimizar exclusivamente por conversión inmediata. Este cambio requiere liderazgo y una cultura de toma de decisiones basada en evidencia y en horizonte temporal compartido.
También es importante la transparencia. Publicar los supuestos del modelo y los resultados de experimentos facilita el entendimiento y reduce la resistencia interna. La atribución no debe ser una caja negra que decide presupuesto sin que otros comprendan sus limitaciones.
Errores comunes y cómo evitarlos
No validar modelos con experimentos. Muchos equipos confían ciegamente en modelos estadísticos sin contrastarlos con pruebas controladas. Esto convierte hipótesis en dogma. Combina modelado con tests para confirmar incrementos reales.
Usar un único criterio de rendimiento. Fijarse solo en CPA o en ROAS corto plazo lleva a decisiones sesgadas. Añade métricas de calidad de leads, retención y CLV para tener una visión más completa del impacto.
Ignorar la pérdida de datos offline. Eventos, ventas en tienda y conversaciones telefónicas pueden explicar gran parte del recorrido. Ignorarlas empobrece la atribución. Integrar CRM y puntos de venta es una prioridad técnica y estratégica.
Checklist para auditoría de atribución
Revisa la integridad de datos entre plataformas, confirma que el CRM está alineado con conversiones digitales y evalúa la presencia de cross-device. Diseña al menos un experimento por canal crítico y documenta supuestos del modelo base. Establece revisiones trimestrales y un proceso de gobernanza con representantes de medios, analítica y dirección.
Si detectas discrepancias fuertes entre plataformas, investiga la causa antes de tomar decisiones drásticas de presupuesto. A veces la solución es técnica y rápida; otras requiere cambio organizativo y tiempo. Mantén comunicación clara sobre incertidumbres y plazos para resolverlas.
Finalmente, prioriza acciones que reduzcan sesgo con mayor palanca: integración de datos, experimentación y formación del equipo en interpretación de modelos. Estos tres frentes aceleran la mejora de tu atribución y la calidad de las decisiones.
Conclusión
El problema central de los modelos de atribución no es que existan; es que se confíe en ellos sin entender sus limitaciones y sin complementar con otras fuentes de evidencia. El sesgo aparece cuando la medición condiciona la realidad y no al revés. Reconocer esto es el primer paso para mejorar la toma de decisiones.
La buena noticia es que hay un camino claro: mejorar la calidad de datos, aplicar modelos con transparencia y validar con experimentación. Métodos avanzados como el valor de Shapley aportan rigor, y la experimentación aporta causalidad. Ninguna de estas soluciones funciona sola; la combinación produce resultados accionables.
Como docente y profesional del sector, te invito a abordar la atribución con pragmatismo crítico. No busques la perfección algorítmica antes de tener datos sólidos y procesos de validación. Prioriza integraciones, diseña experimentos claros y usa modelos para generar hipótesis y optimizar, no para dictar la única verdad. Con ese enfoque, reducirás el sesgo que distorsiona tus resultados y tomarás decisiones más alineadas con el valor real para el negocio.
Referencias
• Kaushik, A. (2009). Web Analytics 2.0. Wiley.
• Shapley, L. S. (1953). A value for n-person games. In H. W. Kuhn & A. W. Tucker (Eds.), Contributions to the Theory of Games (Vol. II). Princeton University Press.
• Kotler, P., & Keller, K. L. (2016). Marketing Management (15th ed.). Pearson.
• Google. (s.f.). Google Analytics Help: Attribution Models. Recuperado de la documentación oficial de Google Analytics.
• Research and practical guidance de fuentes académicas y técnicas sobre medición incremental y diseño experimental, así como documentación de plataformas de analítica y CRM utilizadas por la industria.