




Pruebas A/B: métricas que validan decisiones y evitan suposiciones
Introduccion
Si lideras equipos de marketing o trabajas en estrategia digital, habras vivido la tentacion de interpretar cualquier cambio en conversiones como una victoria o una alarma. Las pruebas A/B prometen objetividad, pero sin las metricas y el diseno adecuados se convierten en una fuente de suposiciones disfrazadas. En este texto vamos a abordar de forma practica y profunda las metricas que realmente validan decisiones y las pautas de diseno que evitan conclusiones apresuradas.
Mi objetivo es ofrecer una guia util para profesionales con alto conocimiento, nada de tutoriales basicos ni tecnicismos vacios. Encontraras criterios claros para elegir metricas, ejemplos aplicables a casos reales de producto y comercio electronico, y recomendaciones sobre interpretacion estadistica que te ayudaran a tomar decisiones con la confianza necesaria dentro de la organizacion.
En el recorrido citare referentes del area cuando aporte valor teorico. No inventare estudios ni cifras, porque la credibilidad de una decision basada en datos se gana con rigor, no con afirmaciones espectaculares. Si al final del texto te quedas con dudas practicas, mi propuesta es siempre validar con un experimento bien planteado antes de generalizar.
Por que las pruebas A/B no son solo cambiar y medir
Un error comun es concebir las pruebas A/B como una tarea operacional: cambiamos la llamada a la accion, medimos conversiones y decidimos. Esta vision falla porque omite la dimension mecanica del comportamiento usuario y la variabilidad inherente a los datos. Las metricas sin contexto llevan a interpretaciones erroneas; hay que entender por que un cambio produce un efecto y en que condiciones ese efecto es reproducible.
Una prueba A/B mal planteada puede generar dos tipos de problemas: decisiones incorrectas por ruido estadistico y falsos descubrimientos por sesgos en el diseno. Para evitarlos hay que definir con claridad la hipotesis, elegir metricas primarias alineadas con el objetivo del negocio y asegurar que la asignacion a variantes sea verdaderamente aleatoria y estable en el tiempo.
Adicionalmente, la comunicacion de resultados requiere traducir el hallazgo a impacto de negocio. No basta con decir que una variacion aumento la tasa de conversion; hay que explicar la magnitud del cambio, su relevancia economica y las condiciones de validez. Esto convierte una prueba en una herramienta de decision en lugar de una curiosidad analitica.
Métricas clave que validan decisiones
Tasa de conversion como métrica primaria
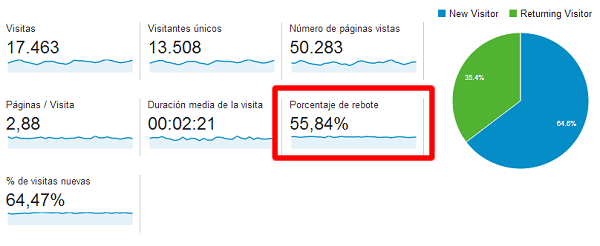
La tasa de conversion suele ser la primera referencia, y con razon: conecta el comportamiento usuario con el objetivo comercial. Sin embargo, elegirla como unica medida puede ser engañoso. Es imprescindible definir exactamente que se entiende por conversion y asegurar que su medicion es consistente entre variantes.
Cuando se usa la tasa de conversion como métrica primaria, hay que complementarla con medidas de magnitud: expresiones absolutas, porcentaje de cambio y confianza en la estimacion. Esto ayuda a distinguir entre cambios estadisticamente significativos pero irrelevantes en terminos de negocio, y cambios de bajo volumen pero con alto impacto economico.
En la practica, para productos de alto valor por transaccion conviene vincular la tasa de conversion a medidas monetarias. Para productos de menor valor o ciclos largos, conviene usar microconversiones relevantes que sean buenos predictores de conversiones finales.
Aumento absoluto y relativo, y por que ambos importan
El aumento relativo (porcentaje) es facil de comunicar y atractivo en reportes, pero el aumento absoluto es el que verdaderamente refleja el impacto real en volumen. Una mejora relativa del 20 por ciento puede ser irrelevante si la tasa base es minima; en cambio un pequeño aumento absoluto sobre una base amplia puede significar un gran beneficio.
Por eso, al presentar resultados muestra siempre ambos valores: la diferencia absoluta entre tasas y el porcentaje de mejora. Complementalo con una traduccion a unidades negocio, como visitas adicionales convertidas o ingreso incremental esperado, para que la decision sea interpretable por stakeholders no tecnicos.
Evita fijarte en mejoras relativas sin contexto. Cuando prepares experimentos, calcula el minimo detectable en terminos absolutos y relativos para saber si tu muestra es adecuada para capturar efectos de interes.
Intervalos de confianza en lugar de p valores unicos
El p valor es comunmente usado para decidir si un efecto es significativo, pero frecuentemente se malinterpreta como la probabilidad de que la hipotesis nula sea cierta. Una aproximacion mas util para la toma de decisiones son los intervalos de confianza: describen un rango plausible para la diferencia entre variantes y comunican incertidumbre de forma mas accionable.
Los intervalos permiten evaluar la precision de la estimacion y si el efecto observado es compatible con umbrales de impacto de negocio. Por ejemplo, si el intervalo incluye cambios negativos relevantes, la prudencia aconseja no desplegar la variacion a produccion aun si el p valor resulto bajo.
Al preparar informes, muestra siempre el intervalo del cambio junto con su interpretacion comercial. Esto facilita que la conversacion en comite se centre en riesgo y beneficio, no en tecnicismos estadisticos.
Potencia estadistica y tamano de muestra
La potencia de una prueba es la probabilidad de detectar un efecto verdadero de determinada magnitud. En la practica, planificar la muestra en funcion de un minimo efecto relevante (MDR o MDE) es esencial. Sin una potencia adecuada, una prueba puede terminar sin conclusiones y generar costes por esfuerzos infrautilizados.
Calcular tamano de muestra requiere una eleccion previa del efecto minimo que considerarias accionable, un nivel de confianza y la variabilidad observada en la metrica. Esta decision debe tomarse antes de iniciar el experimento y documentarse en un protocolo, para evitar cambios post hoc que comprometan la validez.
Si la muestra real resulta menor que la planificada, hay alternativas como prolongar el experimento hasta alcanzar la potencia requerida o replantear la metrica principal por una que tenga menor variabilidad. En cualquier caso, la transparencia sobre potencia evita interpretaciones erroneas de resultados nulos.
Métricas monetarias: ingreso medio por visita y valor de vida de cliente
Cuando el objetivo final es economico, metricas como ingreso medio por visita o valor de vida del cliente aportan una imagen directa del impacto. Son especialmente utiles cuando cambios en la interfaz afectan comportamiento post-conversion, como frecuencia de compra o retencion.
Estas metricas suelen tener mayor variabilidad que la tasa de conversion, por lo que requieren mayor tamaño de muestra o periodo de medicion mas largo. Es habitual monitorizarlas como metricas secundarias durante la prueba y confirmarlas en pruebas de mayor duracion.
Tambien es buena practica transformar ingresos en estimaciones ajustadas, por ejemplo excluyendo outliers o aplicando medians en lugar de medias cuando la distribucion es muy sesgada. La clave es que la metrica refleje el impacto economico real de la variacion.
Engagement y retencion como metricas de sostenibilidad
Una variacion puede mejorar conversiones inmediatas pero perjudicar retencion o engagement, con un coste a medio plazo. Por eso es fundamental incluir metricas que midan comportamiento posterior, como frecuencia de uso, recurrente de compra o tiempo en producto.
Estas metricas requieren ventanas de medicion mayor y a menudo analisis longitudinal. Integrarlas en el protocolo experimental permite detectar efectos adversos que no aparecen en la fase inicial y evita decisiones cortoplacistas que dañen el valor sostenido del negocio.
En la presentacion de resultados, acompana las metricas de conversion con indicadores de calidad de adquisicion para ofrecer una vision completa sobre la conveniencia de desplegar la variacion.
Variacion y desviacion estandar: entender la dispersion
Conocer la variabilidad de la metrica es tan importante como conocer la media. Un efecto puede parecer interesante pero estar acompañado por una dispersion tan amplia que lo hace poco fiable. Por eso conviene reportar la desviacion estandar o medianas intercuartil cuando las distribuciones son no normales.
La dispersion ofrece pistas sobre segmentos con respuesta heterogenea, y sobre la estabilidad del efecto en diferentes condiciones. Si la variabilidad es alta, planteate segmentar el analisis o diseñar pruebas adicionales para comprender la fuente de esa heterogeneidad.
En resumen, integrar medidas de dispersion en los reportes ayuda a los equipos a calibrar el riesgo de una decision y a priorizar acciones de investigacion complementaria.
Diseno experimental que evita suposiciones
Aleatorizacion y asignacion de usuarios
La aleatorizacion es el principio central que convierte una prueba en evidencia causal. Una correcta asignacion aleatoria balancea las caracteristicas observables y no observables entre variantes, reduciendo el riesgo de sesgos. En entornos digitales es importante validar que el mecanismo de reparto no introduce patrones temporales o geograficos.
Verifica que la asignacion sea persistente por usuario para evitar contaminacion cuando un mismo usuario vea diferentes variantes en distintas sesiones. Ademas, monitoriza el balance de caracteristicas clave al inicio del experimento para detectar desviaciones que puedan comprometer la validez.
Documenta y automatiza el proceso de aleatorizacion para reproducibilidad. Si por limitaciones tecnicas no es posible una aleatorizacion perfecta, registra las limitaciones y complementa la prueba con analisis de sensibilidad.
Control de confusores y ventanas de tiempo
Los efectos temporales y externos pueden confundir los resultados. Por ejemplo, promociones, cambios en trafico o variaciones estacionales afectan las metricas. Por eso las ventanas de medicion deben elegirse considerando la estabilidad del trafico y eventos en el calendario que puedan sesgar los datos.
En pruebas largas, divide el experimento en tramos o incorpora covariables temporales en el analisis para ajustar su efecto. Si hay riesgo de eventos externos previsibles, plantea pausas o reruns del experimento para asegurar que el hallazgo sea reproducible.
La transparencia sobre la ventana y el contexto permite a decision makers evaluar la solidez de la evidencia y a los analistas replicar o extender el estudio con mayor confianza.
Pruebas secuenciales y reglas de parada
El deseo de sacar conclusiones rapido lleva a mirar los resultados antes de que termine la prueba. Este comportamiento puede inflar la tasa de falsos positivos. Para evitarlo existen metodos de pruebas secuenciales y reglas de parada predefinidas que controlan el error tipo I bajo revisiones intermedias.
Si optas por monitorizacion continua, usa metodos que ajusten los umbrales o aplica correcciones estadisticas para mantener el control de error. Alternativamente, establece una politica de analisis unica al final del experimento con un tamano de muestra planificado previamente.
Sea cual sea la aproximacion, documentala en el protocolo y comunicala al equipo. La disciplina en el manejo de paradas es parte de la cultura de experimentacion responsable.
Manejo de comparaciones multiples
Cuando comparas varias variantes o realizas muchas metricas secundarias, aumenta la probabilidad de obtener resultados significativos por azar. Este problema de comparaciones multiples exige correcciones o un diseno jerarquico que priorice metricas y contrastes.
Una estrategia practica es definir una unica metrica primaria y limitar las exploraciones secundarias. Para situaciones con varias variantes considera tecnicas de ajuste de p valores o enfoques bayesianos que integren la incertidumbre sin penalizar excesivamente la potencia.
En cualquier caso, comunica claramente que los hallazgos secundarios requieren confirmacion adicional antes de convertirse en decisiones de deploy a gran escala.
Interpretacion y toma de decisiones
Costo de errores y decision informada
No todas las decisiones tienen el mismo coste ante un error. Un falso positivo que implique desplegar una variacion perjudicial puede ser mas costoso que un falso negativo que impida un pequeño beneficio. Por eso, la interpretacion estatistica debe traducirse a escenarios de impacto economico y riesgo operacional.
Incorpora en las reuniones de decision el analisis coste-beneficio. Calcula escenarios pesimistas y optimistas y determina umbrales de accion segun la tolerancia al riesgo de la organizacion. Esto transforma el resultado de la prueba en una decision estrategica, no solo un dato tecnico.
Tambien es util diseñar experiments escalonados: validacion en segmentos controlados antes de un despliegue completo, lo que reduce el riesgo y facilita rollback rapido si aparece un efecto adverso.
Frecuentista versus bayesiano: implicaciones practicas
Las dos corrientes ofrecen herramientas validas para pruebas A/B. La estadistica frecuentista sigue siendo el estandar en muchas empresas por su claridad en criterios de rechazo de hipotesis. El enfoque bayesiano aporta interpretaciones probabilisticas directas sobre la magnitud del efecto, lo que resulta intuitivo para la toma de decisiones.
En la practica, la eleccion depende de la cultura analitica y de las herramientas disponibles. Los metodos bayesianos facilitan la incorporacion de informacion previa y son utiles para decisiones iterativas. Sin embargo, requieren mayor esfuerzo en modelado y comunicacion para ser aceptados por stakeholders acostumbrados a p valores.
Mi recomendacion es utilizar la aproximacion que mejor facilite la comunicacion de incertidumbre y riesgo en tu organizacion, manteniendo rigor en el diseno y coherencia en las conclusiones.
Interpretar tamaño del efecto y relevancia empresarial
Un resultado estadisticamente significativo no siempre es relevante empresarialmente. Valora el tamano del efecto en terminos de ingresos, coste de adquisicion y capacidad operativa. A menudo una mejora marginal puede justificar el despliegue si los costes de implementacion son bajos, y al contrario.
Para tomar la decision define umbrales practicos antes de ejecutar la prueba: cual seria el minimo efecto que haria la accion rentable. Asi evitaras posturas sesgadas que favorezcan resultados atractivos pero no rentables.
Incluye en tu presentacion una seccion que traduzca el resultado experimental a impacto a corto y medio plazo, y propon alternativas de seguimiento si la evidencia es ambigua.
Ejemplos prácticos aplicables
Optimizar una pagina de producto en comercio electronico
Imagina una variacion que cambia la posicion del boton de compra y añade testimonios. La metrica primaria es la tasa de conversion para venta, metricas secundarias son ingreso medio por visita y tasa de devolucion. Antes de arrancar, calcula el tamano de muestra requerido para detectar un efecto que cubra los costes de maquetacion y posibles incrementos en devoluciones.
Durante la prueba monitoriza la dispersion de ingresos y la retencion postcompra. Si observas una mejora inicial en conversiones pero un empeoramiento en devoluciones, la decision no puede tomarse solo con la metrica primaria. Un analisis por segmento (nuevos vs clientes recurrentes) puede revelar que los testimonios influyen de forma distinta y que la estrategia debe ajustarse por grupo.
Finalmente, traduce los resultados a un plan de despliegue gradual y seguimiento. Si el efecto es robusto, despliega primero a un porcentaje controlado del trafico para validar en condiciones de carga real.
Mejorar el embudo de registro en una aplicacion
En pruebas sobre formularios de registro, la tasa de completacion es una metrica natural, pero tambien es clave medir activacion posterior. Un cambio en el numero de campos puede reducir friccion y aumentar registros, pero si los usuarios registrados no se activan, el impacto real es nulo.
Diseña la prueba para capturar activacion en una ventana que refleje el comportamiento tipico de tu producto. Incluye analisis de cohortes para ver si los nuevos registros convierten a usuarios activos en el tiempo. Esta perspectiva evita decisiones optimistas basadas solo en conversiones iniciales.
Si detectas diferencias por canal de adquisicion, plantea pruebas separadas por canal o ajusta la estrategia de despliegue para los canales donde la mejora sea consistente.
Experimento sobre precios y paquetes
Las pruebas de precios requieren especial cuidado porque afectan percepcion y pueden generar efectos de largo plazo. Una opcion es probar cambios en paquetes o presentacion de precios en lugar de modificar el precio base. Las metricas a monitorizar incluyen tasa de compra, ingreso medio por cliente y retencion.
Planifica periodos mas largos y analiza elasticidad por segmentos. A menudo es mejor empezar con un experimento controlado en un mercado o cohortes limitadas antes de escalar. Ten en cuenta tambien regulaciones y comunicacion al cliente si el cambio de precio es relevante.
Cuando reportes resultados, ofrece escenarios economicos y recomendaciones sobre si el cambio debe ser temporal, segmentado o permanente, segun la evidencia acumulada.
Buenas practicas operativas
Protocolos y trazabilidad
Documenta cada prueba con un protocolo que incluya hipotesis, metricas, tamano de muestra, reglas de analisis y cronograma. Esto evita sesgos post hoc y facilita replicacion. La trazabilidad es clave para que cualquier miembro del equipo pueda revisar y validar los pasos del experimento.
Tener un repositorio de experimentos con resultados y comentarios permite aprender de pruebas pasadas y evitar repetir errores. Registra tambien problemas tecnologicos o eventos externos que pudieran haber alterado el experimento.
La cultura de documentacion mejora la calidad de las decisiones y crea un historial util para priorizar futuras pruebas basadas en evidencias previas.
Comunicacion de resultados a stakeholders
Adapta el lenguaje segun la audiencia. Para equipos tecnicos profundiza en supuestos y metricas estadisticas. Para direcciones comerciales traduce el hallazgo a impacto economico, riesgo y recomendaciones concretas. Evita tecnicismos innecesarios en presentaciones ejecutivas.
Incluye siempre una seccion de limitaciones y riesgos para que la decision no sea interpretada como absoluta. Proporciona alternativas de seguimiento y, si procede, planes de rollout gradual con criterios de rollback.
Finalmente, fomenta dialogo y preguntas. Las mejores decisiones surgen cuando el equipo discute implicaciones operativas y comerciales antes de desplegar cambios masivos.
Conclusion
Las pruebas A/B son una herramienta poderosa para validar decisiones, pero solo si se apoyan en metricas relevantes y un diseno experimental riguroso. Elegir la metrica primaria correcta, entender la variabilidad, planificar la potencia y traducir los resultados a impacto de negocio son practicas imprescindibles para evitar suposiciones y decisiones erroneas.
Integra en tu flujo de trabajo protocolos claros, analisis de dispersion y metricas de sostenibilidad como retencion. En la toma de decisiones, considera los costes de errores y utiliza intervalos de confianza y escenarios economicos para comunicar la incertidumbre de forma util y accionable.
Practica la experimentacion responsable: documenta, comunica y escala de forma gradual cuando la evidencia lo justifique. Asi convertirás las pruebas A/B en una ventaja competitiva real para tu empresa, capaz de sostener mejoras continuas y decisiones fundamentadas en datos.
Referencias
• Kohavi, R., Tang, D., y Xu, Y. (2014). Online controlled experiments at large scale. En Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. Nota: referencia al trabajo de Kohavi y colaboradores sobre experimentacion online y buenas practicas.
• Fisher, R. A. (1926). The design of experiments. London: Oliver and Boyd. Clasico sobre principios de diseno experimental, aleatorizacion y controles.
• Montgomery, D. C. (2017). Design and Analysis of Experiments. New York: Wiley. Texto util para tecnicas de diseno, tamano de muestra y analisis estadistico aplicable a pruebas A/B.
• Box, G. E. P., Hunter, J. S., y Hunter, W. G. (2005). Statistics for Experimenters: Design, Innovation, and Discovery. Hoboken: Wiley. Enfasis en la interpretacion practica de experimentos y en consideraciones de aplicacion real.
• Deng, A., y Shi, X. (2016). Practical guidelines for running A/B tests in product teams. Referencia util sobre dimension operativa y comunicacion de resultados, aplicable a equipos de producto y marketing.
• Gerber, A. S., y Green, D. P. (2012). Field Experiments: Design, Analysis, and Interpretation. Nueva York: W. W. Norton. Fuente sobre metodos experimentales en contexto aplicado, con foco en validez y causalidad.
• Hernan, M. A., y Robins, J. M. (2020). Causal Inference: What If. Boca Raton: Chapman & Hall/CRC. Recurso avanzado sobre inferencia causal que aporta perspectiva rigurosa al analisis de experimentos.